- 6 min read
- Aug 29, 2023
- 0

In the era of AI-driven communication and information access, ChatGPT has emerged as a powerful tool for generating text and answering queries. However, with concerns about data privacy and the need for continuous internet connectivity, the concept of crafting a private ChatGPT instance that interacts with your local documents gains traction. This innovative approach not only addresses privacy apprehensions but also provides a more self-reliant way to harness AI’s potential. In this guide, we will delve into the process of creating your own private ChatGPT that seamlessly engages with your local documents, granting you greater control over your data and enhancing your ability to obtain tailored insights.
The structure of a private LLM:
Before diving into the details, let’s outline the components necessary to develop a local language model that can effectively interact with your documents. Imagine having the power of AI right on your computer:
- Open-source LLMs: These compact alternatives to ChatGPT run locally. Examples include GPT4All, and llama.cpp. Trained on extensive text data, they offer high-quality text generation.
- Embedding model: An embedding model all-minilm-l6-v2 transforms text into numerical chromas for easy comparison. Utilizing techniques like word or sentence embeddings, this model enables the identification of related documents. The SentenceTransformers library boasts a variety of pre-trained embedding models.
- Chroma database: This stores and retrieves embeddings, making them comparable. Libraries like Faiss add chroma similarity comparisons to various data stores.
- Knowledge documents: Essential documents for your LLM to reference. They can encompass PDFs, text files, or any relevant content, tailored to your application.
Overview of a LangChain
LangChain has recently become a popular framework for large language model applications. LangChain provides a sophisticated framework to interact with LLMs, external data sources, prompts, and User Interfaces.
How does LangChain work?
LangChain operates based on tokenization, the process of breaking down text into individual units called tokens. In the context of natural language processing, tokens can be words, phrases, or even characters. LangChain’s primary goal is to divide a document into meaningful chunks while minimizing the loss of context.
- Text tokenization: LangChain starts by tokenizing the input document into individual tokens. This step helps identify the boundaries of words, sentences, and paragraphs.
- Chunk creation: The tool then groups these tokens into chunks of a specified maximum token length. This ensures that each chunk is of a manageable size for further analysis.
- Context preservation: What sets LangChain apart is its approach to maintaining context between chunks. It identifies the last complete sentence within a chunk and includes it at the beginning of the next chunk. This way, each chunk starts with a relevant snippet of the previous sentence, ensuring that the language model receives contextual information.
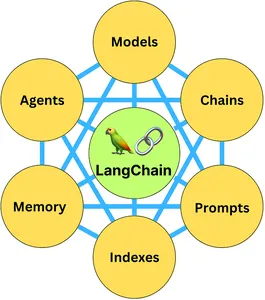
LangChain has six main components to build LLM applications: model I/O, Data connections, Chains, Memory, Agents, and Callbacks. The framework also allows integration with many tools to develop full-stack applications, such as LaaMa, Huggingface Transformers, and chromas stores like chromadb, among others.
Comprehensive explanation of components:

- Model I/O: Interface with language models. It consists of Prompts, Models, and Output parsers
- Data connection: Interface with application-specific data sources with data transformers, text splitters, chroma stores, and retrievers
- Chains: Construct a sequence of calls with other components of the AI application. some examples of chains are sequential chains, summarization chain, and Retrieval Q&A Chains
- Agents: LangChain provides Agents which allow applications to utilize a dynamic chain of calls to various tools, including LLMs, based on user input.
- Memory: Persist application state between runs of a chain
- Callbacks: Log and stream steps of sequential chains in order to run the chains efficiently and monitor the resources consumption
The workflow of a private LLM:
Before you can unleash your local LLM, some initial preparations are necessary:
- Compile a list of documents to form your knowledge base.
- Segment large documents into smaller chunks (around 500 words each).
- Generate embeddings for each document chunk.
- Create a chroma database to store document embeddings.
Now, let’s walk through the workflow of your private LLM:
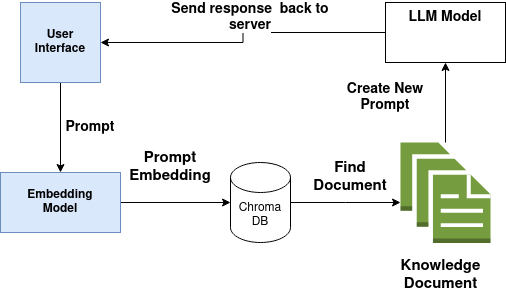
- A user inputs a prompt via the user interface.
- The application employs the embedding model to create an embedding from the user’s prompt and sends it to the chroma database.
- The chroma database responds with a list of documents relevant to the prompt, based on embedding similarity.
- The application crafts a new prompt, combining the user’s initial input with the retrieved documents, and sends it to the local LLM.
- The LLM generates a response along with citations from context documents. The result is presented through the user interface, complete with sources.
Project structure and modules:
1. Dotenv module: The dotenv module is used to load environment variables from a .env file into the process environment. This is particularly useful for managing sensitive information like API keys and configuration settings.
2. RetrievalQA class (langchain.chains module): The RetrievalQA class, likely a part of the langchain.chains module, is designed to facilitate retrieval-based question-answering using language models. It could involve setting up queries, retrieving relevant documents, and generating answers based on user questions.
3. HuggingFaceEmbeddings class (langchain. embeddings module): The HuggingFaceEmbeddings class, likely within the langchain.embeddings module, handles text embeddings using Hugging Face models. It could offer functionalities to transform text into numerical vectors for comparison and analysis.
4. langchain. callbacks.streaming_stdout module: This module, presumably part of your project, could be responsible for managing the streaming of standard output from language models. It might include methods to capture, process, and present the output as it’s generated.
5. Chroma class (langchain.vectorstores module): The Chroma class, found in the langchain.vectorstores module, possibly deals with vector storage and retrieval. It might offer mechanisms to store and query vector embeddings of documents or text segments.
6. GPT4All and LlamaCpp classes (langchain.llms module):
- GPT4All class could represent a specific implementation of a language model, like GPT-4. It might offer methods to interact with the GPT-4 model for text generation and analysis.
- LlamaCpp class, on the other hand, might represent a different language model implementation, possibly utilizing LLMa C++. Similar to GPT4All, it could provide access to LLMa C++ for language-related tasks.
7. Subprocess module: The subprocess module, part of the Python standard library, facilitates the spawning of new processes, connecting to their input/output/error pipes, and obtaining return codes. It could be used to run external commands, potentially for interacting with language models.
8. Shutil module: The shutil module, also a part of the Python standard library, offers high-level file operations for tasks such as copying, moving, and deleting files and directories. It could be used for managing files related to the project, like model files, documents, or temporary data.